
Postavili jsme AI Knowledge Bank za jedno odpoledne
Pondělí odpoledne. Jozo chtěl newsfeed na našem webu. Nejedná se o blog - už máme jeden. Kurátovaná sbírka AI obsahu. Videa, přednášky, interview. Věci, které náš tým skutečně sleduje, aby zůstal aktuální.
"Můžeme to mít do konce dne?"
O dvě hodiny později: 11 kusů obsahu. Pracovní doporučení. Živá na webu.
Tady je, co se opravdu stalo.
Výzva: Přetížení informací
Každý týden desítky důležitých AI videí padá. Přednášky ze Stanfordu. Interview zakladatelů. Technické deep-dives. Analýza odvětví.
Náš tým je sledoval jednotlivě. Sdílení odkazů v Slacku. Ztrácení přehledu o tom, co jsme pokryli.
Problém nebyl v hledání obsahu. Bylo to v jeho organizaci.
Potřebovali jsme centrální místo, kde:
- Kurátovaný AI obsah žije trvale
- Každý kus má kontext (proč záleží, klíčové poznatky)
- Související obsah se objeví automaticky
- Kdokoli v týmu může objevit, co mu chybí
Tradiční řešení znamenala týdny plánování. Systémy správy obsahu. Redakční pracovní toky. Naplánování nástrojů.
Neměli jsme týdny. Měli jsme odpoledne.
Řešení: AI-assisted rapid building
Místo budování platformy obsahu jsme postavili knowledge bank.
Přístup byl jednoduchý: Začněte s jedním videem. Udělejte to správně. Pak škála.
Co jsme postavili
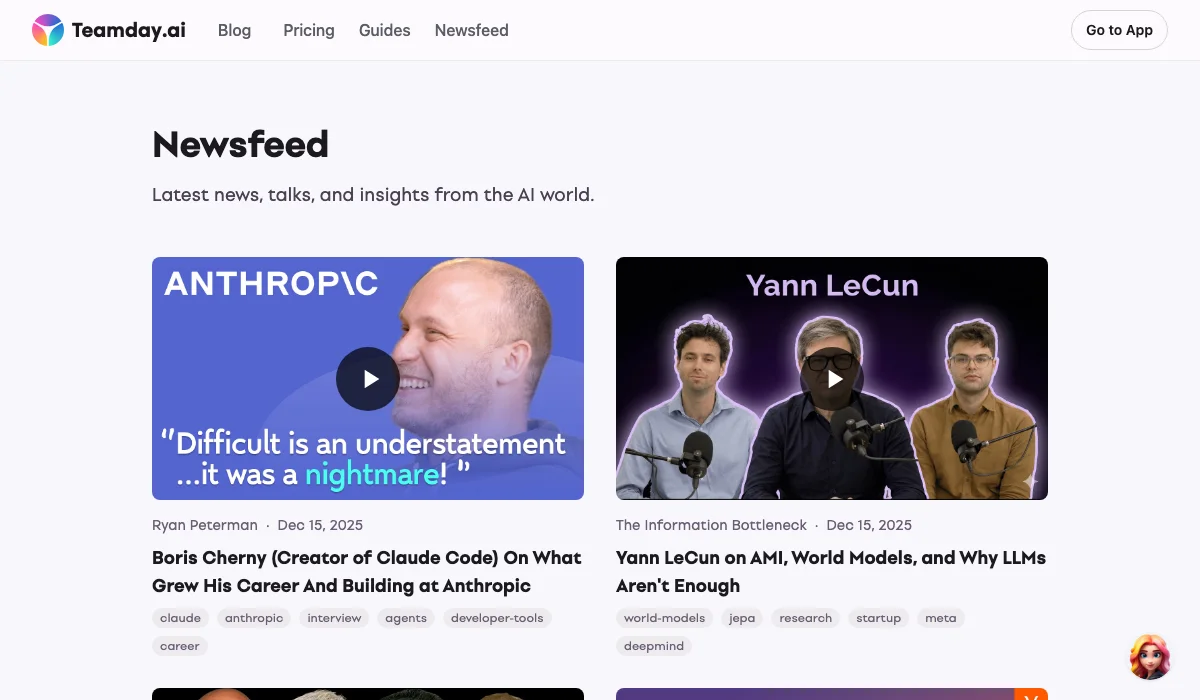
- Kurátovaný newsfeed na /ai/ — Chronologický seznam AI obsahu, který doporučujeme
- Bohatý kontext — Každé video má oddíl "Perspektiva" vysvětlující proč záleží a klíčové poznatky
- Inteligentní doporučení — Související články povrchu na základě skutečné podobnosti obsahu, ne jen tagy
- Transparentní shoda — Uživatelé vidí proč se články doporučují ("87% zápas" vs "52% zápas")
Jak jsme to udělali
Claude zvládl těžké zvedání:
- Extrakce transkriptu — Vytáhněte úplný text z libovolného YouTube videa
- Generování perspektivy — Analyzujte transkript a napište skutečné postřehy
- Paralelní zpracování — Přidejte více videí současně pomocí AI subagentů
- Doporučující engine — Vypočítejte podobnost obsahu a povrchní související kousky
Bez přepisů kódu. Bez nových rámců. Jen AI vyplňující mezery.
Zkušenost: Co to vlastně bylo
První video trvalo asi 15 minut. Stanford CS230 na AI agenty. Vytáhli jsme transkript, vygenerovali perspektivu, přidali jsme ji do newsfeed.
Pak jsme narazili na náš první skutečný problém: Video se nebudelo. Stanford zakázal externí vkládání.
Místo vzdání se jsme postavili fallback. Videa zakázaná vkládáním ukazují náhled s překrytím "Sledovat na YouTube". Uživatelé přesně vědí, na co klikají.
Problém vyřešen za 5 minut.
Škálování
Jakmile se vzor pracoval, Jozo se pokusil zveřejňovat YouTube odkazy:
- Demis Hassabis interview s Axios
- Jensen Huang na AI infrastruktuře
- Peter Diamandis rozebírající GPT 5.2
- Yann LeCun na světových modelech
- Boris Cherny o budování Claude Code
- Rio Lou o designérech stávajících kodérů
Šest AI agentů pracovalo současně. Každý jeden:
- Fetching transkriptu
- Generování perspektivy
- Vytvoření záznamu obsahu
Výsledek: 6 videí zpracováno v čase by trvalo 1 ručně.
Postřeh transparentnosti
V polovině cesty se Jozo zeptal na oddíl "Related Articles".
"Proč se tady zobrazují články? Jaké je spojení?"
Standardní praxe by byla skrýt algoritmus. Jen zobrazit doporučení a důvěřovat, že uživatelé budou klikat.
Udělali jsme opak. Přidali jsme procenta shody.
- 87% shoda — Vysoce související témata
- 52% shoda — Připojeno, stále relevantní
- 34% shoda — Tečný, stále zajímavý
Uživatelé vidí proč něco doporučujeme. Žádná černá skříňka. Žádný tajemný algoritmus.
Ukazuje se, že transparentnost buduje důvěru. Dokonce i když shoda není dokonalá.
Co jsme poslali
Do konce dne byl newsfeed živý na teamday.ai/ai.
11 kurátovaných videí pokrývajících:
- Stanfordské kursy na transformátory a agenty
- Interview zakladatelů (Hassabis, Huang, Brin)
- Analýza odvětví (GPT 5.2 rozpad, AI konkurence)
- Technické debaty (LeCun vs DeepMind na porozumění)
- Vhledy do kariéry (Tvůrce Claude Code, Vůdce designu Cursor)
Každé video zahrnuje:
- AI-generovanou perspektivu proč to záleží
- Klíčové poznatky pro rychlé skenování
- Odkazy na kanál pro objevování více
- Související obsah s transparentní shodou
Nula redakčního pracovního toku. Přidání nového obsahu znamená vytvoření markdown souboru. To je vše.
Klíčové poznatky
1. Začněte s jedním, pak škála
Nestavěte platformu nejdřív. Udělejte jeden kus obsahu dokonale. Vzor se stane jasný. Škálování je snadná část.
2. Nechte AI vyplnit mezery
Nenaučili jsme se editaci videa nebo budování doporučovacích motorů. Použili jsme AI ke zvládnutí toho, co jsme nemohli rychle dělat sami. Výsledek byl lepší než kdybychom to dělali ručně.
3. Transparentnost poráží záhadu
Zobrazování procent shody se cítilo riskantní. Co když uživatelé zpochybňují nízké zápasy? Ukazuje se, že si žádné vážně cení, že proč obsah je doporučen. Důvěra pochází z poctivosti, ne lesku.
4. Paralelní práce změní všechno
Jedna osoba přidávající videa postupně = pomalá. Více AI agentů pracujících paralelně = rychlá. Stejný princip platí pro jakoukoli opakující se znalostní práci.
5. Dost je dobré, perfektní se nešíří
Newsfeed není dokonalý. Některé perspektivy by mohly být hlubší. Nějaké zápasy by mohly být těsnější. Ale je to živý. Je to užitečný. Používá se.
Hotovo poráží dokonalé.
Co dál
Knowledge bank je živý a roste. Přidáváme nový obsah týdně - přednášky, interview, výzkumné rozklady.
Chcete vidět? Podívejte se na AI Newsfeed
Něco podobného budujete? Vzor funguje pro jakýkoli kurátovaný obsah:
- Zpravodaje průmyslu
- Knihovny výzkumu
- Tréninkové zdroje
- Soutěž inteligence
Klíčový vhled: AI nejen píše obsah. Organizuje, spojuje a povrchuje to.
To je budoucnost znalostní práce.
P.S. — Během relace jsme přidali jeden další příspěvek: Rio Lou z Cursor mluví o přeměně designérů na kodéry. Jeho hlavní bod? AI vyplňuje implementační mezery, aby se lidi mohli soustředit na to, co jsou dobré. Přesně to jsme zažili při budování tohoto newsfeed.