
1つの午後でAI知識銀行を構築しました
月曜日午後。JozoはWebサイトでnewsfeedが欲しかった。ブログではなく—私たちはすでに1つを持っています。AIコンテンツのキュレーションコレクション。ビデオ、トーク、インタビュー。私たちのチームが実際に見るもの。
「終わりの日までにできますか?」
2時間後:11のコンテンツ。働く推奨。サイトでライブ。
ここは何が実際に起こったかです。
チャレンジ:情報過載
毎週、何十もの重要なAIビデオドロップ。スタンフォード講義。創設者インタビュー。テクニカル深-dive。業界分析。
私たちのチームは個別にそれらを見ていました。Slackでリンクを共有しました。私たちがカバーされたかを失いました。
問題はコンテンツを見つけていませんでした。それを組織していました。
私たちは、以下の中央の場所が必要でした:
- キュレーションAIコンテンツが永遠に住む
- 各部分には文脈があります(なぜ重要か、重要な取引)
- 関連するコンテンツ自動的に表示
- チーム上の誰でもが彼らが逃したを発見できます
従来のソリューションは数週間の計画を意味していました。コンテンツ管理システム。編集ワークフロー。スケジューリングツール。
我々は数週間を持っていませんでした。午後がありました。
ソリューション:AI-Assisted Rapid Building
コンテンツプラットフォームを構築する代わりに、知識銀行を構築しました。
アプローチはシンプルでした: 1つのビデオから開始。それを作業させる。その場合のスケール。
構築したこと
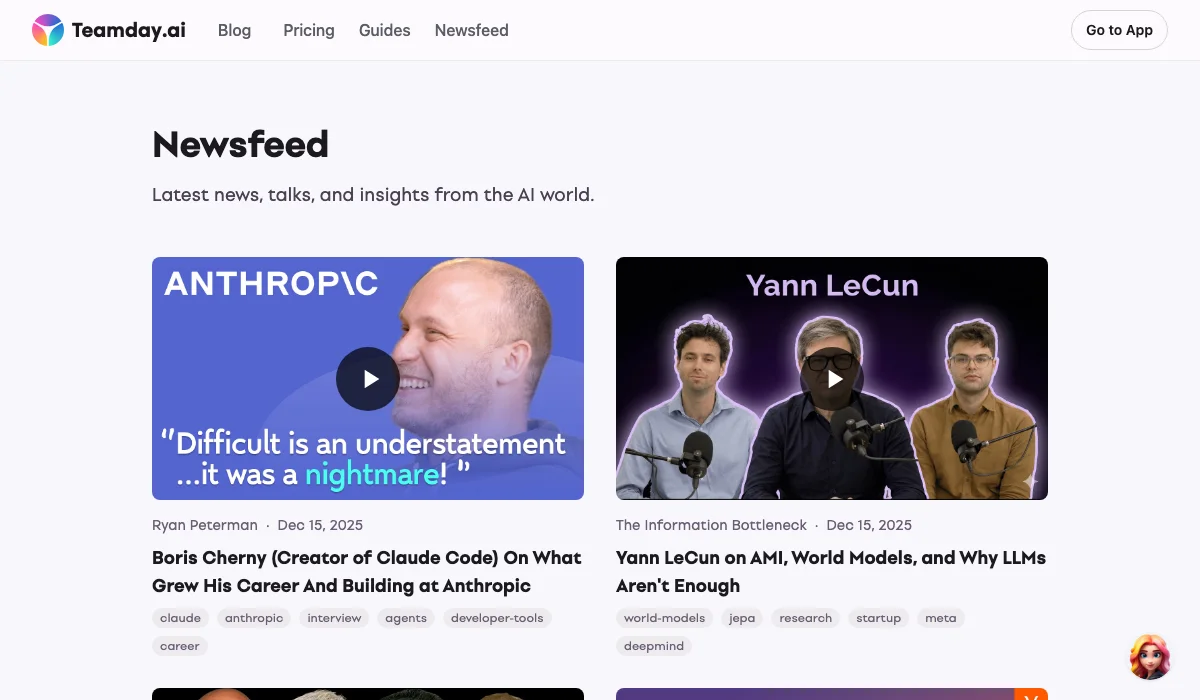
- Curated Feed at /ai/ — AIコンテンツの推奨事項の時系列リスト
- Rich Context — 各ビデオは「パースペクティブ」セクションを持っていて、なぜ重要か主要なポイント
- Intelligent Recommendations —関連する記事の表示はタグに基づいて、実際のコンテンツ類似に基づいて
- Transparent Matching —ユーザーは記事が「87% match」対「52% match」がなぜ関連しているかを見る
私たちはどのようにそれを行いました
Claudeは重い持ち上げを処理:
- トランスクリプト抽出—YouTubeビデオからフルテキストをプル
- パースペクティブ生成—トランスクリプトを分析して本物の洞察を書く
- 平行処理—AIサブエージェントを使用して同時に複数のビデオを追加
- 推奨エンジン—コンテンツ類似性を計算して関連部分を表示
コード書き直しなし。新しいフレームワークなし。ギャップを塞ぐ単なるAI。
経験:実際にどのようなものだった
最初のビデオはおよそ15分かかりました。Stanford CS230 on AI agents。トランスクリプトを引き出した、パースペクティブを生成、feedに追加しました。
その場合、我々は最初の本当の問題に出てきた:ビデオは埋め込まれません。 Stanfordは外部埋め込みを無効にしました。
放棄する代わりに、フォールバックを構築しました。埋め込まれたビデオを無効にした埋め込まれたビデオサムネイルを表示します。ユーザーが知っている正確に彼らが何をクリックしているか。
5分間で問題が解決されました。
スケーリング
パターンが機能したら、私たちはビデオを平行に追加しました。Jozo kept dropping YouTubeリンク:
- Demis Hassabis with Axios
- Jensen Huang on AI infrastructure
- Peter Diamandis breaking down GPT 5.2
- Yann LeCun on world models
- Boris Cherny on building Claude Code
- Rio Lou on designers becoming coders
6つのAIエージェント同時。それぞれ1つ:
- トランスクリプト取得
- パースペクティブ生成
- コンテンツエントリ作成
結果:6つのビデオが1つを手動で行う時間に処理。
Transparency Insight
途中で、Jozo About about「Related Articles」セクションを尋ねました。
「Why are these articles showing up?Connection what's?」
標準的な実践は、アルゴリズムを隠すことです。推奨を表示し、ユーザーがクリックするかをクリックすることに信頼。
私たちはしました反対。 マッチパーセンテージを追加しました。
- 87% match —非常に関連するトピック
- 52% match —接続、関連
- 34% match —接線、まだ興味深いかもしれない
ユーザーはなぜ我々が何かを推奨しているかを見ます。ブラックボックスなし。謎のアルゴリズムなし。
透明性は信頼を構築するターンアウトします。 マッチングが完璧でもない場合。
出荷したもの
日の終わりまでに、newsfeedはlive at teamday.ai/ai。
11キュレーションビデオ 覆い:
- Stanford courses on transformers and agents
- Founder interviews (Hassabis, Huang, Brin)
- Industry analysis (GPT 5.2 breakdown, AI competition)
- Technical debates (LeCun vs DeepMind on understanding)
- Career insights (Claude Code creator, Cursor's design lead)
各ビデオが含む:
- AIが生成されたパースペクティブに重要なのか
- スキャンするための重要な取引
- チャンネルリンク詳細を発見
- 透明マッチングを使用して関連するコンテンツ
Zero editorial workflow。 新しいコンテンツを追加するのは、Markdown fileを作成することを意味します。それだけです。
キーテイクアウェイ
1. 1つで開始し、その場合のスケール
最初にプラットフォームを構築しません。完璧に動作するコンテンツの1つのピースを作ります。パターンが明確になります。スケーリングは簡単です。
2. AIギャップを埋めるようにしてください
我々はビデオ編集を学びました、推奨エンジンを構築しませんでした。AIが迅速に自分たちが自分たちができなかったことを処理することを使用。結果は手動で行われたほうが優れていました。
3. 透明性はミステリーをビート
マッチパーセンテージを表示するのはリスキーでした。ユーザーが低match質問場合はどうですか?オープンしているので、ユーザーがなぜコンテンツが推奨されているかを知っていることを感謝します。信頼は秘密からではなく、誠実さから来ます。
4. 平行的な仕事はすべてを変える
1つの人が順序順番でビデオを追加=遅い。複数のAIエージェントが平行で機能=高速。同じ原則はあらゆる繰り返し知識を適用します。
5. 良好な出荷、完璧ではない
newsfeedは完璧ではありません。いくつかのパースペクティブはより深くすることができます。いくつかの試合はきつくすることができます。しかし、それはライブです。便利です。使用されています。
Done beats perfect。
次は何?
知識銀行はライブと成長しています。週間を追加新しいコンテンツ—トーク、インタビュー、研究の故障。
見たいですか? チェックAI Newsfeed
同様のものを構築していますか? パターンは任意のキュレーションコンテンツに対して機能します:
- 業界ニュースフィード
- 研究図書館
- トレーニングリソース
- 競争インテリジェンス
重要な洞察:AIはコンテンツを書くだけではありません。それを組織し、接続し、表示します。
これが知識仕事の未来です。
P.S. —セッション中に1つのビデオを追加しました:Cursor from Rio Lou 設計者をコーダーに変えることについて話しました。主なポイント? AIが実装ギャップを埋めるので、人々は彼らが得意なことに焦点を当てることができます。正確に私たちはこのnewsfeedを構築しながら経験した。