
2026年版:エージェンティック・コーディング完全ガイド
ちょうど1年前、Andrej Karpathyがさりげなく一つの革命に名前を付けました:バイブコーディング。今日、彼はその後継者を指名しています:エージェンティック・エンジニアリング。この変化は単なる言葉の問題ではありません。AIを使ってプロフェッショナルがソフトウェアを構築する方法の根本的な変化を表しています。
このガイドでは、エージェンティック・コーディングをマスターするために必要なすべてをカバーします:概念、パターン、ツール、そしてAIエージェントを使ってプロダクションシステムを構築する実践者から得た貴重なベストプラクティスです。
エージェンティック・コーディングとは?
エージェンティック・コーディングは、AIエージェントがコーディングタスクを自律的に処理するソフトウェア開発アプローチです。人間の介入を最小限に抑えながら、計画・実行・反復を行います。
単一の提案を行う従来のAIコーディングアシスタントとは異なり、エージェンティック・コーディングのエージェントは継続的なフィードバックループの中で動作します:
- タスクと周辺のコンテキストを分析する
- アプローチを計画する(ファイルの変更、依存関係、アーキテクチャ)
- コードを書いたり、修正したり、削除することで実行する
- 結果をテストする(ビルドの実行、テストの実行、出力の確認)
- タスクが完了するまでフィードバックに基づいて反復する
重要な違い:あなたはコードを書くのではなく、コードを書くエージェントを指揮するのです。
エージェンティック・コーディングの三本柱
Apiiroのセキュリティ研究によると、エージェンティック・コーディングは三本の柱の上に成り立っています:
| 柱 | 説明 | あなたの役割 |
|---|---|---|
| 自律性 | エージェントはコードアプローチについて独立した判断を下す | 境界と目標を定義する |
| コンテキスト | エージェントはコード、依存関係、システム要件を分析する | 明確なプロジェクト構造を提供する |
| 制御 | ガードレールが安全性とコンプライアンスを確保する | レビュープロセスを確立する |
三つすべてが連携して機能するとき、妥協なしのレバレッジが得られます。いずれかが失敗すると、技術的負債、セキュリティの脆弱性、あるいはより深刻な問題が生じます。
バイブコーディング vs エージェンティック・コーディング:進化

Karpathyの振り返りがその違いを完璧に捉えています:
「当時(2025年2月)、LLMの能力は十分に低かったため、バイブコーディングは主に楽しみのためのスロー・アウェイプロジェクト、デモ、探索に使われていました。楽しい体験で、ほぼ機能していました。今日、LLMエージェントを通じたプログラミングはプロフェッショナルのデフォルトワークフローとして定着しつつあり、ただしより多くの監視と精査を伴っています。」
| 側面 | バイブコーディング | エージェンティック・コーディング |
|---|---|---|
| 目標 | とりあえず動かす | 妥協なしのプロ品質 |
| 用途 | デモ、プロトタイプ、実験 | プロダクションシステム、エンタープライズソフトウェア |
| ワークフロー | 説明 → 生成 → 雰囲気確認 | 設計 → 指揮 → テスト → レビュー |
| 品質基準 | 「ほぼ動いた」 | 「プロダクション基準を満たす」 |
| エンジニアの役割 | プロンプト作成 + パッチ適用 | 設計 + 指揮 + レビュー |
| エラー率 | 約40%高い脆弱性率 | 体系的レビュー + 自動スキャン |
エージェンティック・コーディングの目標は明確です:ソフトウェア品質を妥協することなく、AIエージェントのレバレッジを得ること。
5つのエージェンティック・パターン

Anthropicの研究は、エージェンティックシステムを構築するための5つの基本パターンを特定しています。これらを理解することで、各タスクに適切なアプローチを選択できます。
1. プロンプト・チェーニング
概要: タスクを順次ステップに分解し、各LLM呼び出しが前の出力を処理します。
使用場面: 明確な段階があるタスク — コンテンツ生成、多段階変換、文書処理。
ワークフロー例:
1. アウトライン生成 → 2. セクションの展開 → 3. 整合性チェック → 4. 出力フォーマット
トレードオフ: レイテンシは増加しますが、精度は向上します。各ステップを独立して最適化・検証できます。
2. ルーティング
概要: 入力を分類して専門化したハンドラーに振り分けます。
使用場面: 異なる入力タイプが異なる処理アプローチを必要とする場合。
例:
ユーザーリクエスト → 分類器
├── バグ修正 → デバッグエージェント
├── 新機能 → アーキテクチャエージェント
├── リファクタリング → リファクタリングエージェント
└── 質問 → リサーチエージェント
重要な理由: ある入力タイプへの最適化が他のタイプのパフォーマンスを低下させることを防ぎます。
3. 並列化
概要: 複数のLLM呼び出しを同時に実行します。
二つのアプローチ:
- セクション分割: タスクを独立したサブタスクに分割し、並列実行して結果をマージ
- 投票: 同じタスクを複数回実行し、信頼度のために集計
使用場面: 独立したサブタスク(ファイル分析、テスト生成)や高い信頼度が必要な場合。
4. オーケストレーター・ワーカー
概要: 中央のLLMがタスクを動的に分解し、専門化したワーカーに委任します。
使用場面: ステップ数を事前に決定できない複雑で予測不可能なタスク — コーディングプロジェクト、リサーチタスク。
アーキテクチャ:
オーケストレーター(計画 + 調整)
├── ワーカー1:ファイル分析
├── ワーカー2:コード生成
├── ワーカー3:テスト作成
└── ワーカー4:ドキュメント
これはほとんどのエージェンティック・コーディングツールが使用するパターンです。
5. エバリュエーター・オプティマイザー
概要: 一つのLLMが出力を生成し、別のLLMが反復ループで評価・フィードバックを提供します。
使用場面: 洗練が必要なタスク — コードレビュー、コンテンツ編集、最適化問題。
例:
ジェネレーター:関数を書く
↓
エバリュエーター:エッジケース、セキュリティ、スタイルをレビュー
↓
ジェネレーター:フィードバックに基づいて修正
↓
(品質基準を満たすまで繰り返す)
エージェンティック・コーディングのツール
Claude Code
Anthropicのエージェンティック・コーディング用公式CLIです。ファイルシステムとコマンドへの完全アクセスでターミナル上で動作します。
主な特徴:
- 複雑な推論のための拡張思考
- コンテキスト認識による複数ファイル編集
- ツール使用(bashコマンド、ファイル操作)
- 外部統合のためのMCP(Model Context Protocol)
- プロジェクト固有の指示のためのCLAUDE.mdファイル
最適な用途: ターミナルワークフローに慣れた、最大の制御を求める開発者。
Cursor
VS Code上に構築されたAIファーストのコードエディターです。IDEの利便性で複数のモデルを統合します。
主な特徴:
- 複数ファイルのエージェントタスクのためのComposer
- インライン補完とチャット
- コードベース全体のコンテキスト
- 複数モデルのサポート(Claude、GPTなど)
最適な用途: IDE統合ワークフローを好む開発者。
GitHub Copilot(エージェントモード)
Copilot WorkspaceによるエージェンティックなGitHubのAIアシスタントです。
主な特徴:
- IssueからPRへのワークフロー
- 複数ファイルの計画と実行
- GitHub統合(PR、issue、actions)
- VS CodeとJetBrainsのサポート
最適な用途: すでにGitHubエコシステムにいるチーム。
Cline
エージェンティック・コーディングのためのオープンソースVS Code拡張機能です。
主な特徴:
- 自律的なタスク実行
- ブラウザ自動化のサポート
- 複数のモデルバックエンド
- 完全に透明な操作
最適な用途: カスタマイズオプションを持つオープンソースツールを求める開発者。
その他の注目ツール
- Aider: Git統合によるターミナルベースのペアプログラミング
- Continue: 複数モデルをサポートするオープンソースIDE拡張機能
- Codex (OpenAI): 自律的なコーディングタスクのためのクラウドベースエージェント
- Amazon Q Developer: AWS統合コーディングエージェント
実践者からのベストプラクティス
これらの推奨事項は、エージェンティック・コーディングでプロダクションシステムを構築している開発者 — Simon Willison、Armin Ronacher、そしてAnthropicチーム — から来ています。
1. シンプルに始め、必要な時だけ複雑さを加える
「LLMの分野での成功は、最も洗練されたシステムを構築することではありません。あなたのニーズに合った適切なシステムを構築することです。」 — Anthropic
エージェントに手を伸ばす前に試してみてください:
- 良いコンテキストを持つ単一の最適化されたプロンプト
- 関連情報のための検索拡張(RAG)
- フォーマットとスタイルのためのフューショット例
シンプルなアプローチが明らかに機能しない場合にのみ、エージェンティック・パターンを追加してください。
2. LLM消費のためのツール設計
エージェントツールは人間向けのAPIとは異なる設計原則が必要です:
すべきこと:
- 各ツールに徹底的なドキュメントを書く
- 構造化フォーマットではなく自然なフォーマット(散文、markdown)を使用する
- アクションを出力する前に「考える」ためのトークンをモデルに与える
- 情報的なメッセージでエラーを適切に処理する
すべきでないこと:
- 正確な行数や文字位置を要求しない
- 複雑な計算やエスケープが必要なフォーマットを使用しない
- モデルが最初から正しくツールを使用すると仮定しない
Armin Ronacherの原則:「ツールはLLMのカオス・モンキーが完全に間違った方法で使用することから保護される必要があります。」
3. すべてを観測可能にする
エージェントが自律的に動作する場合、何をしているかを可視化する必要があります。
実践的なアプローチ:
- すべての出力をターミナルとログファイルの両方にパイプする
- 複数のソース(サーバー、テスト、ビルド)からのログを統合する
- エージェントの計画ステップを明示的に表示する
- 実行されたコマンドとその結果を記録する
Simon Willisonのテクニック:統合ロギングを使用してエージェントが自分の操作を監視し、エラーから回復できるようにする。
4. ガードレールを付けて実行する
システムへの完全アクセスを持つエージェントは強力であり、危険でもあります。自分を守ってください:
開発のために:
- 隔離のためにDockerコンテナを使用する
- サンドボックス環境でエージェントを実行する
- ファイルシステムアクセスをプロジェクトディレクトリに制限する
- 実行前にコマンドをレビューする(または承認ワークフローを使用する)
プロダクションのために:
- 生成されたコードにセキュリティスキャンを実装する
- 型システムを使用してコントラクトを強制する
- 自動化テストを検証ゲートとして使用する
- 機密操作には人間によるレビュー
5. エージェントを助ける言語を選ぶ
一部の言語とフレームワークはエージェントとの相性が他より優れています。
エージェントに適したもの:
- Go: 明示的なコンテキスト、直接的なテスト、構造的インターフェース
- TypeScript: 強力な型がエージェントのミスを早期に検出
- Rust: コンパイラが正確性を強制
エージェントにとって難しいもの:
- 「マジック」の多用(pytestフィクスチャ、Railsの慣習)
- 複雑な非同期パターン
- 深いフレームワーク抽象化
Ronacherの洞察:「巧妙なクラスより、シンプルで説明的な関数名を好む。複雑なORMより平易なSQLを使用する。権限チェックをローカルで可視的に保つ。」
6. 速度が重要
高速なフィードバックループが生産的なエージェンティック・ワークフローを可能にします:
- 高速コンパイル: エージェントは素早いビルドでより速く反復できる
- 高速テスト: エージェントは頻繁に変更を検証できる
- 高速なツール応答: ハングするツールはエージェントのフローを壊す
ツールチェーンが遅い場合、エージェントは苦労します。ビルド最適化に投資してください。
7. 並列化のために共有状態を分割する
複数のエージェントを実行する場合:
- しないこと: エージェントに同じデータベース、ファイルシステム、リソースを競わせない
- すること: 各エージェントに隔離された状態を与える(別々のデータベース、ディレクトリ)
- すること: 定義された同期ポイントで結果をマージする
これにより競合が防がれ、真の並列作業が可能になります。
エージェンティック・エンジニアリングのワークフロー
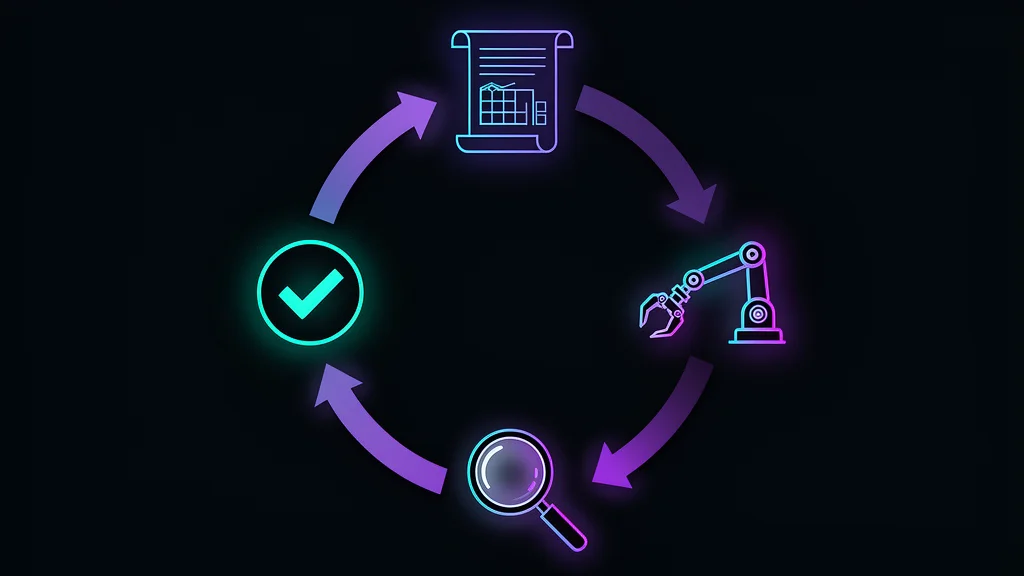
経験豊富な実践者が仕事をどのように構造化するかを紹介します:
フェーズ1:ソリューションを設計する
あなたが行うこと。 定義する:
- データモデルとAPIコントラクト
- コンポーネントの階層と境界
- エラー処理パターン
- セキュリティ要件
エージェントに曖昧なプロンプトを与えないでください。正確な仕様を与えてください。
フェーズ2:実装を指揮する
エージェントが行うこと。 実行する:
- 複数ファイルにわたるリファクタリング
- 型安全なマイグレーション
- テストカバレッジの拡大
- ドキュメントの更新
エージェントはあなたのアーキテクチャとの一貫性を維持しながら機械的な作業を処理します。
フェーズ3:テストと検証
あなたが行うこと。 確認する:
- エージェントが考慮しなかったエッジケース
- 現実的な負荷下でのパフォーマンス
- セキュリティへの影響
- ユーザーエクスペリエンスのフロー
QAとして機能し、何を調整する必要があるかについて具体的なフィードバックを提供する。
フェーズ4:レビューと承認
あなたが行うこと。 確認する:
- プロジェクト基準に対するコードパターン
- アーキテクチャの一貫性
- セキュリティの脆弱性
- 長期的な保守性
エンジニアが最終承認ゲートです。これを省略しないでください。
よくある落とし穴とその回避方法
落とし穴1:時期尚早な複雑さ
問題: よく作られたプロンプトで十分なときに、洗練されたマルチエージェントシステムを構築してしまう。
解決策: 最もシンプルなアプローチから始める。測定可能な限界に当たったときだけ複雑さを追加する。
落とし穴2:盲目的な信頼
問題: レビューなしにエージェントの出力を受け入れる。「コンパイルが通ったからリリースしよう。」
解決策: すべての変更をレビューする。エージェントが生成したコードのパターン認識を磨く — 一般的な失敗モード、セキュリティの脆弱性、アーキテクチャのドリフト。
落とし穴3:プロジェクト構造が不十分
問題: エージェントは乱雑なコードベース、不明確な慣習、ドキュメントの欠如に苦労する。
解決策: プロジェクトの衛生に投資する:
- 明確なファイル構成
- プロジェクト慣習を持つCLAUDE.mdまたは同等のもの
- 型定義とインターフェース
- 包括的なテストスイート
構造化されたプロジェクトはより優れたエージェントパフォーマンスを可能にします。
落とし穴4:不十分なテスト
問題: 検証なしにエージェントが「うまく機能する」ことに依存する。
解決策: 自動化テストはさらに重要になります:
- ユニットテストがロジックエラーを検出する
- 統合テストがコンポーネントの相互作用を検証する
- E2Eテストがユーザーワークフローを検証する
- セキュリティスキャンが脆弱性を特定する
テストはエージェントがミスをしたときのセーフティネットです。
落とし穴5:コンテキストの過負荷
問題: エージェントに多すぎるコンテキストを与え、混乱や品質の低下を引き起こす。
解決策:
- 関連するファイルにエージェントの注意を向ける
- 孤立したリサーチタスクにはサブエージェントを使用する
- コンテキストを切り替えるときに会話履歴をクリアする
- 簡潔で的を絞った指示を提供する
落とし穴6:放棄されたパターン
問題: エージェントがパターンを導入し、あなたは先に進み、古いパターンがコードに残る。将来のエージェントが古いパターンをコピーする。
解決策: 積極的にリファクタリングする。複雑さが積み重なる前にコンポーネントを抽出する。非推奨のパターンを長引かせない。
セキュリティの考慮事項

エージェンティック・コーディングは独自のセキュリティ課題をもたらします。Apiiroの研究が強調しています:
| リスク | 説明 | 軽減策 |
|---|---|---|
| 脆弱性の導入 | エージェントがセキュリティ上の欠陥を持つコードを生成する可能性 | 自動セキュリティスキャン、コードレビュー |
| 審査されていない依存関係 | エージェントがセキュリティレビューなしにライブラリを追加する可能性 | 依存関係ポリシー、ロックファイル |
| ビジネスロジックの欠陥 | エージェントが要件を誤解する可能性 | 徹底的な仕様、検証テスト |
| エラーのエスカレーション | 小さなエージェントのミスが急速に複合する | インクリメンタルな変更、頻繁な検証 |
| データ露出 | エージェントが機密データをログに記録または露出する可能性 | 明示的なデータ処理ルール、監視 |
ベストプラクティス: エージェントが生成したコードは、新しいジュニア開発者からの貢献に適用するのと同じ精査で扱ってください — すべてを検証する。
成功の測定
エージェンティック・コーディングが機能しているかどうかはどうやって分かりますか?
生産性メトリクス
- 機能までの時間: 要件から動くコードまでどのくらいかかりますか?
- 反復速度: アイデアをどれだけ早く試して検証できますか?
- コード量: セッションごとにどれだけの機能的なコードが生産されますか?
品質メトリクス
- バグ率: エージェントは手動コーディングより多くのバグを導入していますか?
- セキュリティの発見: 脆弱性スキャンはより多くの問題を検出していますか?
- 技術的負債: コードは長期的に保守可能ですか?
学習メトリクス
- エージェントの精度: エージェントは最初の試みで正しい出力をどのくらいの頻度で生産しますか?
- 修正の労力: エージェントのミスを修正するのにどれだけの時間がかかりますか?
- パターン認識: エージェントの問題を発見することが上手くなっていますか?
時間をかけてこれらを追跡してください。生産性が向上しながら品質メトリクスが低下している場合、隠れた負債を蓄積しています。
エージェンティック・コーディングの未来
2026年以降についてのKarpathyの予測:
「モデル層と新しいエージェント層の両方でさらなる改善が見られると思います。両者の積と、もう一年の進歩に興奮しています。」
利益は複合します:
- より良いモデル = より長い自律的なタスク期間、より少ないミス、より深いコンテキスト理解
- より良いエージェント指揮 = マルチエージェントの協調、特化したツール使用、改善された監視システム
- 両者が合わさって = より良いモデルがより洗練されたワークフローを可能にし、新しい能力を明らかにするフィードバックループ
すでにこれを目にしています:VS Codeが「エージェントセッション」を出荷し、GitHub Copilotが複数のエージェントバックエンドをサポートし、OpenRouterがタスク固有の最適化のために100以上のモデル間でルーティングしています。
エージェンティック・コーディングは周辺的な実験ではありません — プロフェッショナルがソフトウェアを構築するデフォルトの方法になりつつあります。
始め方:最初の1週間
1〜2日目:セットアップと基本
- エージェンティックツールをインストールする(Claude Code、Cursor、またはCline)
- 実験用のサンドボックスプロジェクトを作成する
- 基本タスクを実行する: ファイル作成、シンプルな編集、コマンド実行
- 観察する: エージェントはどのように推論しますか?どんなミスをしますか?
3〜4日目:プロジェクト統合
- プロジェクトドキュメントを追加する(CLAUDE.mdに慣習、パターン)
- 実際のタスクを試す: コードベースのバグ修正または小さな機能
- レビューを練習する: エージェントが行うすべての変更を精査する
- 反復する: エージェントの動作に基づいてプロンプトを洗練する
5〜7日目:ワークフロー開発
- パターンを確立する: どの種類のタスクがうまく機能しますか?どれがより多くの監視を必要としますか?
- ガードレールを構築する: 自動化テスト、セキュリティスキャン、レビューチェックリスト
- 測定する: 節約された時間と修正の労力を追跡する
- 調整する: データに基づいてアプローチを洗練する
結論:「ほぼ動いた」から「動く」へ
1年前、バイブコーディングは最先端でした — 速く、楽しく、脆弱でした。今日、エージェンティック・エンジニアリングはプロフェッショナルの基準です — 体系的で、厳格で、信頼性があります。
この転換は重要です。目標は単なる速度ではありません — それは犠牲なしのレバレッジです。プロフェッショナルなソフトウェアエンジニアリングの品質基準を維持しながら、AIエージェントの生産性の恩恵を得られます。
これには新しいスキルが必要です:
- エージェントが正確に実装できるソリューションの設計
- 複雑で多段階のタスクを実行するためのエージェントの指揮
- ミスが複合する前に検出するためのスケールでのレビュー
- 時間をかけてエージェントのパフォーマンスを向上させるフィードバックループの設計
これらは些細なスキルではありません。深い技術的知識が必要です — エージェントがそれを生産したときに認識するために、良いコードがどんなものかを理解する必要があります。
しかし、レバレッジは本物です。一人のエンジニアが、以前は全チームが必要だったシステムを維持できます。AIが完璧なコードを書くからではなく、エンジニアが設計、指揮、テスト、監視の維持方法を知っているからです。
問題はエージェンティック・ワークフローを採用するかどうかではありません。うまく行うためのスキルを開発するかどうかです。
リソース
公式ドキュメント
実践者ガイド
- Simon WillisonによるエージェンティックコーディングについてのPost
- Armin Ronacherのエージェンティック・コーディング推奨事項
- Karpathyのバイブコーディングからエージェンティック・エンジニアリングへ
ツール
- Claude Code - AnthropicのCLIエージェント
- Cursor - AIファーストのコードエディター
- Cline - オープンソースVS Code拡張機能
- Aider - ターミナルペアプログラミング
関連記事
- バイブコーディングからエージェンティック・エンジニアリングへ - 1年間の進化
- OpenRouterの最良AIモデル - エージェンティック作業のためのモデル選択